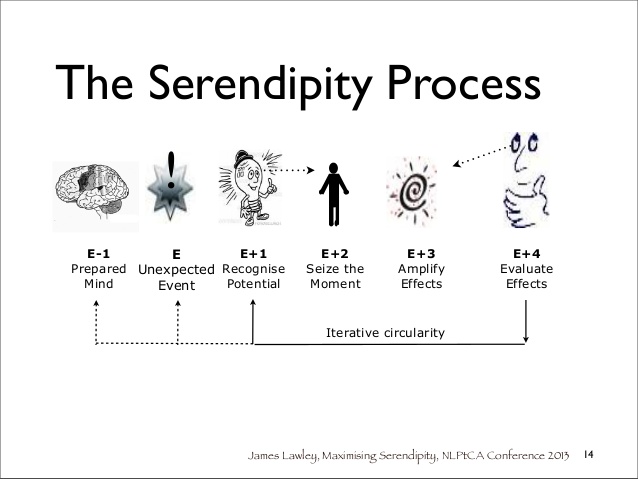
Les Data, le nouvel or noir de notre économie.
Ces quatre lettres font régulièrement parler d’elles tant au niveau national qu’international. Vues comme des sources financières à fort potentiel par les entreprises et les GAFAM (Google, Amazon, Facebook, Apple, et Microsoft) notamment, ce sont souvent les personnes privées qui en font les frais, parfois à leur insu le plus total. Le Federated Learning vise à diminuer le risque de perte de données sensibles en modifiant la manière d’entrainer les algorithmes sur les données des utilisateurs.
Nous mettons souvent en avant le terme Donnée, alors qu’il existe quatre éléments différents : la donnée, l’information, la connaissance et la sagesse. Chaque éléments ajoutant de la valeur au précédent. Explications :
La donnée est la forme la plus brute, c’est-à-dire qu’elle n’est qu’une valeur sans signification propre. Prenons en exemple le mot « rouge ». Cette valeur peut concerner un stylo, une pomme ou encore un pot de peinture. C’est pourquoi il faut ajouter un contexte afin d’en tirer une information.
Prenons l’exemple d’un feu de signalisation qui est au rouge. Maintenant, l’information est compréhensible, car, grâce à l’ajout de la signification, nous pouvons créer un lien avec ce que nous appréhendons afin d’obtenir la connaissance de la valeur rouge. Comme nous sommes probablement en train de conduire une voiture lorsque le feu de circulation passe au rouge, notre connaissance nous informe qu’il faut nous arrêter. Alors intervient la sagesse qui nous pousse à nous arrêter effectivement au feu rouge.
Cette démarche s’applique dès qu’il y a une donnée, peu importe sa nature. Si cette dernière n’est pas contextualisée, on ne peut pas l’utiliser en l’état. De même, une information à laquelle nous n’arrivons pas à joindre une signification ne peut pas être utilisée. C’est le cas actuellement des approches Big Data ; cependant, dans ce cas-là, l’objectif est de récupérer beaucoup d’informations et de les stocker de manière centralisée dans des Data Lakes sans savoir comment les utiliser lors de leur récupération.
De l’apprentissage machine centralisé à l’apprentissage fédéré
C’est là que Machine Learning, ou apprentissage automatique, entre en jeu. Le Machine Learning est un « Processus par lequel un algorithme (également appelé modèle) évalue et améliore ses performances sans l’intervention d’un programmeur, en répétant son exécution sur des jeux de données massifs jusqu’à obtenir, de manière régulière, des résultats pertinents ».
Avec l’augmentation de la quantité de données et du fait qu’elles se retrouvent dans quasiment tous les domaines, le problème actuel n’est pas de trouver des données à analyser, mais bien de trouver comment analyser toutes ces données et dans quel but. Se pose alors le problème de la récolte et de la transmission de nos données en vue d’une exploitation ultérieure dont le but nous échappe souvent.
C’est là que l’apprentissage fédéré révèle sa valeur puisque par nature, il permet de protéger les données des utilisateurs en évitant de les transférer sur un serveur d’entreprise (le fameux “Cloud“) comme le font les algorithmes utilisés jusqu’alors. Ainsi, l’utilisateur qui reste maître de ses données.
L’apprentissage fédéré est un algorithme entrainé sur des appareils décentralisés et utilisant les données locales pour apprendre. Contrairement à la grande majorité des algorithmes actuels qui utilisent un serveur contenant toutes les données, le Federated Learning apprend sur les données locales et communique uniquement ce qu’il a appris. Ainsi, les données restent privées, car elles ne sont plus collectées ni stockées sur un serveur distant.
Le secret de l’apprentissage fédéré ?
Plutôt que de centraliser les données pour y entrainer un algorithme central, l’apprentissage fédéré consiste à entraîner un algorithme sur la machine des utilisateurs d’une application et à partager ensuite les apprentissages ainsi réalisés.
Un avantage indéniable de cette technologie est la protection des données des utilisateurs. Comme le modèle apprend sur la machine des utilisateurs, il n’y a plus de transfert d’informations brutes, mais uniquement du modèle entrainé. L’avantage secondaire de cet atout est que les données ne transitent plus entre l’appareil et le serveur de l’entreprise et les risques de piratage par écoute sont donc diminués. De plus, comme les données ne sont plus stockées sur les serveurs de l’entreprise, les risques de piratage de ces derniers en sont d’autant diminués.
Autre avantage, puisque le Federated Learning ne transfert que le modèle entrainé, les coûts de communication sont moindres. C’est un élément qui peut être très intéressant pour les réseaux saturés ou peu fiable.
Attention toutefois, cette approche de l’apprentissage fédéré ne vise pas forcément à remplacer l’apprentissage automatique tel qu’il est existe aujourd’hui. Il s’agit d’une nouvelle approche qui offre un certains nombres d’avantages mais qui possède également ses limites intrinsèques, notamment concernant les possibilités de vérifier le modèle généré puisque les données qui ont permis de l’entrainer ne sont plus accessibles.
Le fait que l’apprentissage fédéré soit à l’aube de son existence explique pourquoi la technologie est peu connue du grand public et du monde professionnel. Avec les bonnes applications et les bons cas d’utilisation, son adoption pourrait bien se répandre durant ces prochaines années au sein des professionnels de l’informatique et de la sécurité des données.









 La famille est venue dans ce coin paradisiaque pour la randonnée et la découverte de la nature. Véronique souffre quelque peu de problème de genoux et de vertige. Elle bénéficie de l’appui de l’application
La famille est venue dans ce coin paradisiaque pour la randonnée et la découverte de la nature. Véronique souffre quelque peu de problème de genoux et de vertige. Elle bénéficie de l’appui de l’application 
 En se renseignant à l’Office du Tourisme, Véronique découvre que le village propose un service de navettes autonomes,
En se renseignant à l’Office du Tourisme, Véronique découvre que le village propose un service de navettes autonomes,