
Tous les objets de notre quotidien deviennent connectés : notre voiture, maison, four, cuisinière, lave-linge, vélo, tv, nous pouvons aussi l’être au travers d’un bracelet connecté ! Tous ces capteurs génèrent un volume de données titanesque qui double tous les ans, celles-ci s’apparentent au nouveau pétrole du 21ème siècle.
Dès lors, comment les entreprises réussissent-elles à acquérir un tel gisement ? Comment transformer ces données en “Smart Data” ? Quel est l’impact sur son modèle d’affaires ? Et quels en sont les risques ?
Je commence cette année avec une série de réflexions et de partage d’expériences sur ce thème, en débutant tout naturellement par le premier enjeu : Comment acquérir une masse considérable de données nommée “Big Data” ou “mégadonnées” ?
Les entreprises possédant ces Big Data se verront accorder un avantage concurrentiel considérable, pour autant qu’elles soient ensuite capables de les valoriser. Ce phénomène touche tous les domaines, de la publicité ciblée à l’industrie 4.0 en passant par la médecine personnalisée et l’agriculture de précision.
Dès lors, quelles stratégies mettre en place pour créer un tel gisement de données ? Prenons trois exemples de domaines, la santé, la publicité en ligne et la mobilité.
1. Constituer une biobanque mondiale de génomes
La médecine va être transformée par les acteurs qui arriveront à obtenir ce Big Data. En effet, pour proposer une médecine prédictive et par la suite, une médecine préventive, l’industrie a besoin d’entrainer ces algorithmes avec un nombre de données considérables. De nombreux acteurs s’attaquent à ce marché avec des stratégies différentes, en voici deux exemples :
La première approche : agréger les données collectées par les hôpitaux.
Les hôpitaux universitaires comme le CHUV constituent des biobanques sur la base volontaire des patients. En développant des partenariats avec les hôpitaux, on peut arriver à concentrer une masse de données élevées. Pour obtenir ces données, des solutions de stockage, de partage sécurisé des données et des analyses des résultats du séquençage du génome sont proposées aux hôpitaux. C’est l’approche choisie par la startup vaudoise Sophia Genetics, qui a déjà signé des contrats avec plus de 400 établissements.
La deuxième approche : proposer un service pour lequel le client doit fournir ses données
Pour 99.- USD, la startup 23andme vous propose de connaître vos origines sur les 200 dernières années. On peut ainsi découvrir que nos origines sont par exemple, en majorité suédoise et danoise, mais qu’on a des descendants italiens. Dès cette année, on peut également obtenir des informations telles que le risque d’avoir une maladie génétique comme Parkinson ou sa prédisposition à être plus maigre ou plus gros que la moyenne. Le processus est très simple, il suffit de commander un kit dans lequel se trouve une éprouvette. On y met un peu de salive et on la renvoie. Au maximum deux mois plus tard, on a les résultats en ligne. En proposant ce service, 23andme a déjà collecté plus d’un million de génomes.
2. Connaître toutes nos actions sur internet
Comme deuxième perspective, regardons un domaine plus mature, celui de la publicité avec le cas de Google. Son modèle d’affaires est centré sur la donnée, plus de 80% de son revenu est généré en monétisation son Big Data, par la vente de publicités ciblées en ligne. Comment ont-ils fait pour accéder à ce “Big Data” ?
- L’accès au flux de données sur nos ordinateurs : Google a introduit gratuitement le navigateur Chrome en 2008. Le graphique suivant montre l’évolution des parts de marché des différents navigateurs internet : en 10 ans, Google Chrome a capturé presque 80% du marché.
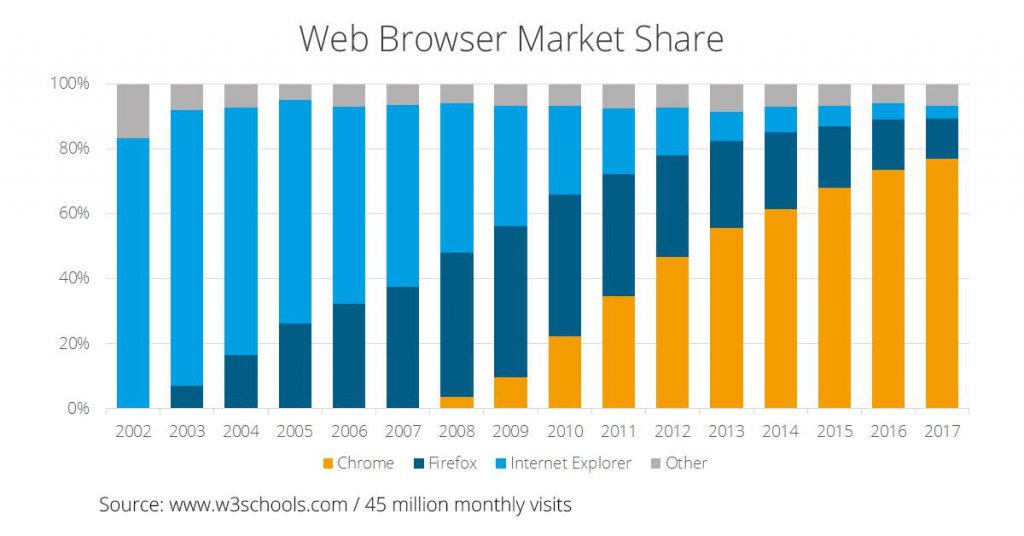
- L’accès au flux de données sur nos mobiles : Google a racheté la startup Android en 2007 et son système d’exploitation est actuellement utilisé sur plus de 80% des smartphones.
Chrome et Android sont donc les interfaces qui permettent à Google d’acquérir une masse considérable de données sur nos activités. La firme de Cupertino est donc parvenue à obtenir une part de marché telle qu’elle est maintenant devenue incontournable. On peut même résumer la stratégie de Google d’accès à la donnée par la citation de Peter Thiel (dont je lis actuellement le livre “Zero to One”) : “la compétition est pour les perdants, créer plutôt un monopole”.
3. Capter les données de la mobilité du futur
Les voitures deviennent toutes connectées à leur environnement et elles renvoient des données en continu. Des applications multiples vont voir le jour : par exemple, si l’on obtient l’information sur le déclenchement des essuie-glaces d’un grand nombre de voitures, on serait en mesure de cartographier en temps réel la position et le déplacement des orages.
Trois exemples de stratégies pour accéder à ce Big Data :
- Google (encore!) veut rentrer dans nos voitures et propose Androidauto, qui, de la même manière qu’avec Chrome ou Android, lui permettra de capter nos données
- Tesla propose un véhicule connecté et de plus en plus autonome qui intègre son propre système d’exploitation. Tesla a bien compris qu’elle doit garder le contrôle des données produites par ces véhicules
- Proposer un service innovant de mobilité sur la base d’une plateforme qui collectent toutes les informations de mobilité. C’est la stratégie adoptée par des sociétés comme Uber ou Lyft. Uber propose déjà ces données anonymisées, Uber Movement, dans le but d’améliorer la planification urbaine.
En conclusion, j’ai pris trois secteurs en exemple, mais l’enjeu de réussir à accumuler un Big Data est présent dans tous les domaines. Les stratégies d’acquisition de données sont multiples, mais comme le montre le domaine de la publicité en ligne, les sociétés qui auront anticipé cette tendance se retrouveront dans une situation favorable. Il y a peut-être aussi une deuxième question à se poser : est-ce qu’une répartition très polarisée du Big Data est susceptible de créer des déséquilibres économiques et sociétaux ?
En lien ci-dessous, ma présentation sur ce thème au Swiss Data Day de l’EPFL en novembre dernier :