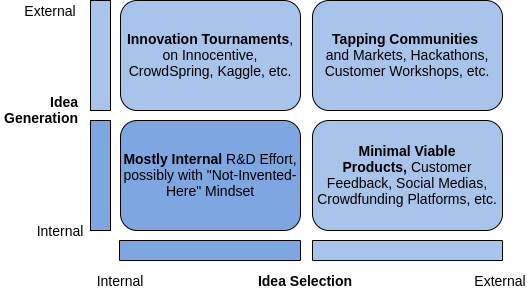
Cet article porte sur les méthodes de gestion de l’innovation dans les entreprises, c’est-à-dire le processus qui consiste à rendre ou à maintenir une entreprise de toute taille créative et donc compétitive. Il fait partie d’une série d’articles que je publie sur Medium (en anglais) comme support pour ma classe de troisième cycle à l’université que j’enseigne pendant mon temps libre.
Mes articles sont basés sur la littérature actuelle dans le domaine ainsi que sur ma propre expérience en entrepreneuriat et de conseils aux entreprises (profile LinkedIn). La version originale de cette article (en anglais) est disponible ici (ainsi que les liens sur les autres articles de cette serie).
L’énigme de la collaboration
La plupart des innovations importantes qui nous entourent, sinon toutes, résultent de l’interaction entre des entités, parfois avec des objectifs différents voire concurrents. En d’autres termes, elles se produisent rarement dans le vide. Pourtant, la collaboration est souvent considérée comme une énigme : elle fonctionne mieux en théorie qu’en pratique.

Photo by Perry Grone on Unsplash
Lorsque ces interactions sont le résultat d’un ensemble de collaborations axées sur des objectifs mais peu coordonnées, on parle de collaboration ouverte. Vous trouverez plusieurs définitions de la collaboration ouverte sur Wikipédia et d’autres ressources en ligne. Les exemples typiques sont les logiciels open source, les forums et les communautés en ligne. Comprendre le modèle de collaboration ouverte peut être une clé pour résoudre l’énigme.
Dans cet article, j’examine dans quelles conditions une collaboration ouverte se déroule idéalement et comment recréer ces conditions afin qu’elles puissent être utilisées comme un mécanisme efficace pour stimuler la créativité, par exemple dans un contexte entrepreneurial ou universitaire. En outre, lorsque la collaboration ouverte cède le pas au cas plus étroit de l’innovation collaborative (aussi appelé innovation ouverte, ou Open Innovation en anglais), j’examine les ingrédients supplémentaires et nécessaires pour favoriser un résultat bénéfique entre les participants, en particulier du point de vue de la propriété intellectuelle.
Qu’est-ce qu’une collaboration ouverte ?
Comme je l’ai mentionné dans l’introduction, une collaboration ouverte est définie comme la mise en place d’une série d’interactions peu coordonnées entre les participants, cependant avec un objectif commun.

Photo par Salmen Bejaoui sur Unsplash
Ainsi, en vertu de ce principe, une collaboration ouverte n’est pas nécessairement déclenchée de manière explicite, mais plutôt un processus émergent qui a lieu dans certaines circonstances, par exemple un besoin survenant dans un cadre communal ou un problème qui doit être résolu par consensus. Pensez à un groupe de petites et moyennes entreprises désireuses de partager leurs savoir-faire ou leurs ressources.
Le résultat de la collaboration offre un large éventail de possibilités : il peut s’agir simplement d’un accord, d’un consensus sur le savoir-faire ou d’une politique, mais aussi d’un nouveau produit ou service. Le fait que l’un de ces résultats soit mutuellement bénéfique pour les participants ou qu’il soit déséquilibré dépend d’un facteur important : la transparence.
Le développement de logiciels open source en est un parfait exemple et représente souvent l’exemple même de la collaboration de masse donnant lieu à des logiciels parfois d’une complexité impressionnante. Le but du projet GNU est de fournir un cadre pour de telles collaborations dans le but de “donner aux utilisateurs d’ordinateurs la liberté et le contrôle de l’utilisation de leurs ordinateurs et de leurs appareils informatiques en développant et en publiant en collaboration des logiciels qui donnent à chacun le droit d’exécuter librement le logiciel, de le copier et de le distribuer, de l’étudier et de le modifier“. (Wikipédia)
Le cadre informel d’une collaboration ouverte constitue souvent un processus hautement distribué qui peut être utilisé comme un système d’innovation, c’est-à-dire un ensemble de méthodes de création, pouvant être exploité par les entreprises ainsi que par les institutions universitaires et de recherche.
En règle générale, la collaboration ouverte entre entreprises ou dans un cadre universitaire va du partage d’informations au développement conjoint d’un nouveau produit par les participants, qui peuvent intégrer des contributions provenant d’efforts de collaboration de masse tels que l’open source, les “creative commons” ou les efforts de crowdsourcing.

Photo par Rob Curran sur Unsplash
C’est ainsi que la collaboration ouverte se rapporte à l’innovation collaborative (Open Collaboration), un sujet que j’aborde en détail dans un article précédent. Une innovation de produit ou de service est l’un des résultats possibles (et peut-être le plus marquant) d’une collaboration ouverte.
Cependant, la mise en œuvre d’une stratégie d’innovation collaborative réussie requiert un peu plus d’attention que la mise en place d’une collaboration ouverte. Alors, commençons par collaborer !
La confiance est la clé
Pour que la collaboration ouverte se produise en tant que processus émergent, c’est-à-dire en dehors d’un mécanisme de contrôle clair, un catalyseur important pour une collaboration ouverte réussie est la confiance.
Qu’elle soit déplacée ou non, il est peu probable qu’une collaboration ait lieu sans que les participants aient confiance en leur capacité à obtenir un résultat mutuellement bénéfique. Un mécanisme de vérification peut atténuer la probabilité d’un résultat défavorable pour l’une ou l’autre des participants. Ronald Reagan aimait citer un vieux proverbe russe “faire confiance mais vérifier” (trust but verify) lors des négociations du désarmement nucléaire avec les Soviétiques à l’époque de la guerre froide.
Le domaine de la cybersécurité et les mécanismes conçus par ses praticiens sont devenus une partie essentielle d’un appareil de vérification dans un monde où les collaborations se font principalement par le biais de dispositifs informatiques.

Photo par Nick Fewings sur Unsplash
Dans un cadre entrepreneurial, par exemple lorsque des entreprises décident de collaborer à un projet technique, un environnement de collaboration (cyber)sécurisé permet aux participants de s’assurer que, en s’ouvrant aux apports extérieurs et en fournissant des résultats, elles peuvent le faire de manière inoffensive. Il existe toute une série de préjudices possibles, mais les plus courants sont : la perte de la propriété intellectuelle, des actifs de l’entreprise ou même de la compétitivité. De plus, dans un environnement de conformité de plus en plus difficile, la fuite de données telles que les informations personnelles identifiables (IPI) peut être financièrement graves pour l’entreprise qui la subit, car de lourdes amendes sont infligées pour violation du règlement général sur la protection des données ou GDPR.
Il est évident que tous les préjudices susmentionnés peuvent être causés sans qu’il y ait collaboration (c’est-à-dire uniquement par des acteurs internes), mais le fait de faire entrer des personnes extérieures dans le “périmètre” de l’entreprise entraîne sans aucun doute de nouveaux défis et menace généralement la sécurité de l’entreprise.
Dans un cadre universitaire, la confiance est également un facteur déterminant. Toute institution universitaire disposant d’un financement important aspire à un classement décent parmi ses pairs. Par conséquent, sa réputation sera influencée par sa capacité à collaborer avec l’industrie. Ainsi fournir un environnement sécurisé (par exemple pour les données, les codes et d’autres actifs) ne peut qu’améliorer sa capacité à inciter ses partenaires industriels à partager des données du monde réel, ce qui permet à l’institution de collaborer sur des problèmes eux-aussi, du monde réel.
Il convient de mentionner que le mouvement Open Data joue un rôle d’équilibriste nécessaire qui atténue certaines des préoccupations relatives à la protection des données privée que j’ai évoquées plus haut. En particulier pour assurer le respect des règles lors du traitement des informations nominatives, le processus d’anonymisation des données joue également un rôle important de passerelle.
Il est ironique de constater que le processus d’ouverture de la collaboration entre les entreprises exige en fait que nous mettions en place de nombreux garde-fous supplémentaires !
Le lien avec la cybersécurité
Voyons maintenant comment la notion de confiance se traduit dans le monde de la cybersécurité. Mon but ici est seulement de donner un aperçu des ingrédients les plus importants et les plus nécessaires pour permettre une collaboration ouverte et sûre, et en aucun cas d’être exhaustif.

Photo de Kyle Glenn sur Unsplash
La notion de gestion des identités et des accès (souvent désignée par son acronyme IAM) est essentielle à la gestion des accès aux ressources informatiques. L’objectif de l’IAM est de faire en sorte que les utilisateurs, qu’ils soient externes ou internes, aient un accès contrôlé basé sur le principe du moindre privilège, c’est-à-dire qu’ils n’aient accès qu’aux ressources (ordinateurs, biens, documents, etc.) qui sont nécessaires à leur rôle et à leur mission. Dans le cas d’une collaboration ouverte, la nécessité de garder une vue claire de qui a accès à quoi (par exemple, documents de conception, notes de réunion, etc.) semble simple, mais un temps et des capacités techniques limité et parfois la négligence en font une corvée redoutable.
En particulier, l’accès aux systèmes informatiques est aujourd’hui possible grâce à des identifiants qui peuvent prendre plusieurs formes : paires utilisateur/mot de passe, clés cryptographiques, données biométriques, etc. La gestion des identifiants et des clés et, en particulier, la possibilité de révoquer l’accès en désactivant un identifiant est un élément important à la sécurité pour garder la collaboration ouverte sous contrôle.

Photo par Jason Leung sur Unsplash
Récemment, la nécessité d’un processus spécifique pour gérer les menaces d’initiés a pris de l’importance au sein de la communauté de la cybersécurité. Comme son nom l’indique, l’objectif est ici d’atténuer tout effet potentiellement néfaste qu’un initié malveillant pourrait causer. L’initié est ici un employé ou plus généralement toute personne qui pourrait avoir accès aux actifs de l’entreprise, comme dans le cas d’une collaboration ouverte. Les méthodes de gestion des menaces d’initiés et des attaques ciblées sont regroupées sous la discipline de l’analyse du comportement des utilisateurs. Elles consistent généralement à surveiller les activités d’un utilisateur et à déterminer si ses activités s’écartent d’un modèle de comportement “normal”.
Jusqu’à présent, les mécanismes de cybersécurité que j’ai mentionnés sont utiles pour gérer une collaboration ouverte impliquant le partage d’idées, de discussions, de documents de conception et de ressources informatiques.
Les ingrédients supplémentaires ci-dessous sont nécessaires lorsque la collaboration va plus loin et implique la création d’actifs tangibles tels que du codes informatique, un concept de produit ou d’autres artefacts permettant de capturer des connaissances concrètes, c’est-à-dire convergeant vers l’innovation collaborative.
Les pratiques de développement sûres, en particulier pour le code informatique, apportent une couche de confiance pour un champ d’application élargi de la collaboration ouverte. Certaines des disciplines de la cybersécurité qui sont pertinentes pour notre problème sont par exemple l’analyse de la composition des logiciels (j’y reviendrai dans le paragraphe suivant), les outils de gestion de la vulnérabilité des logiciels et les mécanismes de contrôle de la traçabilité des versions de développement des logiciels. Cette dernière fonction est foournie avec l’utilisation de logiciels tels que git et n’est souvent pas immédiatement perçue comme un mécanisme de sécurité. Cependant, elle joue un rôle central dans la sécurisation du développement de logiciels en offrant une protection contre les pertes dues à une mauvaise manipulation. Elle est également à la base de la construction ou de l’intégration de mécanismes de sécurité supplémentaires.

Photo par Eric TERRADE sur Unsplash
En résumé, pour toutes les parties collaboratrices, le niveau de maîtrise des disciplines de la cybersécurité que j’ai mentionnées ci-dessus influencera le niveau de confiance qui sera accordé à la collaboration ouverte qui s’instaure entre elles.
L’un des avantages immédiats qui découlent d’un mécanisme de vérification solide est la traçabilité. En particulier, la capacité à retracer les contributions de données (idées, documents, codes, etc.) tout au long du déroulement de la collaboration est en fait une clé pour transformer une collaboration ouverte en un processus d’innovation collaborative. Dans le dernier exemple de création de code informatique que j’ai mentionné, la pratique consistant à utiliser des outils de contrôle de version distribués permet aux parties collaboratrices de retracer clairement les contributions individuelles au code (lorsque le système gère les identités des contributeurs). Ceci nous amène au prochain sujet de notre discussion.
Comment pratiquer l’innovation collaborative dans le cadre de collaborations ouvertes
J’ai expliqué dans l’introduction que la collaboration ouverte est une voie naturelle vers l’innovation collaborative, c’est-à-dire basée sur l’utilisation des ressources externes. La collaboration prend également des formes multiples : entre entreprises homologues, lors d’une initiative d’outsourcing, entre entreprises de tailles différentes, etc.

Photo par Manja Vitolic sur Unsplash
En fait, pour concevoir une stratégie d’innovation collaborative, une entreprise doit envisager de multiples mises en œuvre, chacune impliquant une forme différente de collaboration. Celles que j’ai mentionnées ci-dessus ne constituent qu’un sous-ensemble des possibilités. Dans mon précédent article “Open Innovation: Qu’est-ce qu’une stratégie d’innovation ouverte?“, je présente un revue approfondie et une classification des différents types d’innovation collaboratives et des types de collaboration qu’elles nécessitent.
L’une des principales considérations lorsqu’on innove collaborativement est de savoir si l’effort conduit à la création de propriété intellectuelle.
Les actifs de propriété intellectuelle (PI) sont un élément clé de la stratégie concurrentielle de la plupart des entreprises. Pour tous les scénarios d’innovation ouverte que j’envisage ici, une préoccupation légitime est de savoir comment la propriété intellectuelle est partagée entre les participants. Pour répondre à cette question, nous devons réfléchir à la participation de chaque participant. Faire de cette réflexion un après-coup est souvent synonyme de désastre et nuit au mécanisme de vérification de la confiance. Aujourd’hui, ce problème est surtout traité par des documents juridiques et des accords préalables. Cependant, ce mécanisme n’est pas à l’abri de litiges car les relations sont parfois durables avec les changements de membres de l’équipe (ce qui entrave généralement la révision des contributions). De plus, l’évolution des positions compétitives des participants sur le marché peut entraîner des changements de stratégie.
Les questions que j’ai évoquées ci-dessus sont valables à la fois dans les milieux industriels et universitaires. De plus, la portée des contestations de licences pourrait ne pas se limiter aux participants impliquées dans la collaboration. Comme je l’ai expliqué précédemment, l’utilisation de composants logiciels open source est devenue routine pour continuer à innover dans un monde numérisé de plus en plus complexe. La discipline de l’analyse de la composition des logiciels que j’ai mentionnée précédemment met en lumière la complexité du traitement des licences des composants de logiciels open source. J’écris sur les questions liées aux logiciels à source ouverte (y compris leurs dangers) dans mon précédent article sur l’innovation collaborative.

Photo par Hitesh Choudhary sur Unsplash
Le traitement des questions liées à la propriété intellectuelle et à l’octroi de licences dans le cadre d’une collaboration ouverte fait appel à de nombreux mécanismes numériques, dont certains sont encore à l’état embryonnaire. On s’attend à ce que la gestion de la propriété intellectuelle soit également numérisée. Cela permet à son tour d’utiliser des techniques d’apprentissage automatique (Machine Learning) pour automatiser le traitement et l’analyse. En particulier, les mécanismes qui offrent certaines garanties d’immuabilité des données, tels que la Block Chain, sont considérés pour permettre d’enregistrer tout type de biens afin de traçer la PI. Cela permet de retracer la création de la PI tout au long du déroulement du projet de collaboration ouverte que j’ai mentionné précédemment. En substance, l’objectif est de suivre les idées et leurs auteurs depuis le début du projet.
Évaluation de la performance de la collaboration
Un dernier point que je voudrais aborder dans cet article est l’évaluation des performances de la collaboration.
En fonction de la relation entre les participants impliquées dans la collaboration ouverte, il pourrait être intéressant de contrôler les performances des différents contributeurs. Cela pourrait être particulièrement intéressant lorsque le cadre est plutôt déséquilibré, comme dans le cas de l’externalisation du développement (outsourcing).
Un cadre de collaboration ouverte que j’ai brièvement mentionné précédemment est celui où une entreprise externalise une partie de son développement à une entreprise externe.
L’externalisation est devenue un élément de la stratégie standard des entreprises. Toute mise en œuvre prudente de la stratégie met en balance un ensemble de risques bien compris et la l’attrait financier potentiel.

Photo par Alexander Redl sur Unsplash
Dans ce cas, il est probable qu’un contrat soit mis en place avec un certain type d’attentes sur la performance de l’entité contractuelle. Dans ce cas, la performance est généralement mesurée à l’aide d’un outil de gestion de projet qui permet à l’entreprise de suivre l’achèvement des tâches externalisées. Il est intéressant d’envisager la mise en place d’un mécanisme similaire dans le cas d’une collaboration ouverte “équilibrée”, par exemple entre pairs. Ce mécanisme peut être mis à profit dans le cadre du défi relatif à la propriété intellectuelle que j’ai mentionné précédemment.
C’est tout pour cet article. Les défis que la collaboration ouverte et un de ces resultats: l’innovation collaborative, apportent aux entreprises ne sont certainement pas limités à ceux que j’ai passés en revue dans cet article. Cependant, il est clair que la confiance est un catalyseur majeur pour permettre la collaboration, qu’elle soit ouverte ou fermée, et qu’elle est le ciment d’une collaboration réussie. La transparence est également un catalyseur qui renforce la notion de confiance dans la plupart des cas. Certains des mécanismes apportés par la cybersécurité sont un moyen de concrétiser cette confiance dans le monde réel.
Commentaires, réactions : Laurent Balmelli (Twitter Laurent Balmelli)









 Photo par
Photo par